
Data Scientists, Machine Learning engineers, and so on, code programs that are going to be used in some sort of application. This means that the better they are at professional software development, they better and more comfortable they are going to feel at their jobs.
Knowing and implementing the best possible software development practices and being comfortable with coding, looking up documentation, and so on, is something that can take a Data Scientist from good to great, and I think that a bachelor or a degree in Computer Science gives its student just that.
If you have a different background, or don’t have the chance to study computer science, you shouldn’t worry tough. In this post I will try to give you the practical tools and the theoretical topics that you should master in order to make wonderful code as a Data Scientist. We will not go into depth on any of them, but It should give you an idea of the areas that you should look into to enhance and perfect your developing practices.
TLDR, the topics we will cover are:
- Find, fix and optimise your IDE.
- Know which environments are for which tasks: Notebooks
- Correctly set up your working environments
- Learn GIT and use some sort of version control
- The SOLID Principles
- Learn Object Oriented Programming
- Find comfort in the command line
- Training on the push of a button
- Training and Application
- Extras: Testing, CI/CD…
Awesome, now that you know the topics we will cover, lets dive right into them:
1. Find, fix and optimise your IDE
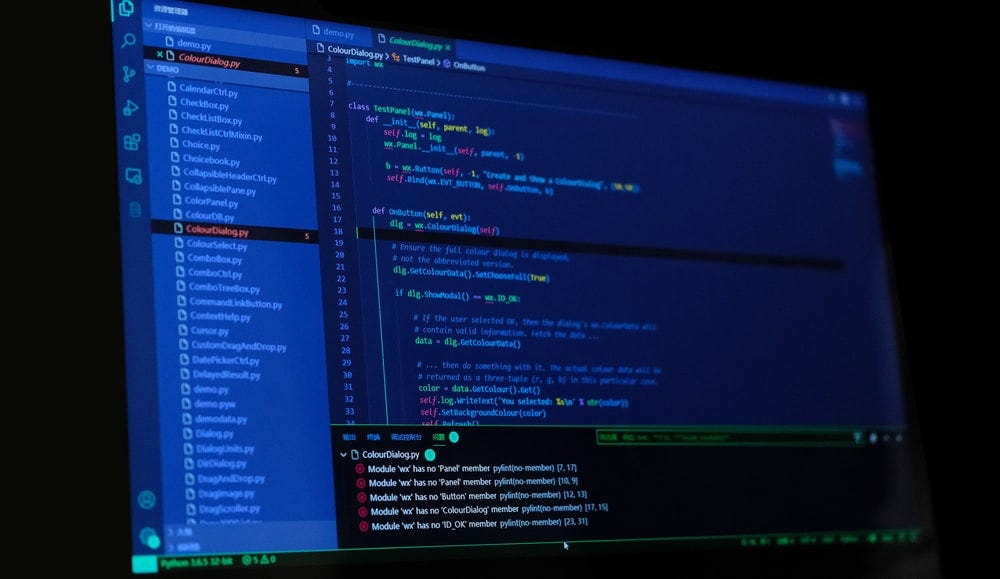
IDEs or Integrated Development Environments are the tools or applications that software developers use to program.
There is a really wide variety of them, and finding the one we feel the most comfortable with can be a daunting task. This search is something that is highly personal. For example, I like using Pycharm for big projects, and Sublime text for quick snippets and tests.
Once you have found your de-facto IDE, it is time to configure it. The goal of this step is to make it look awesome, pleasing, tidy, and clean.
Also, aside from the aesthetics, you should customise the keyboard shortcuts, install ad-dons, and all the other functionalities that will make your work more efficient and make you more productive as a programmer. This is highly personal too, so try out a few different builds, experiment shortcuts and configurations until you find what works best for you.
Here are a list of great IDEs that you can check out:
They all have their different pros and cons: Notepad ++, Sublime and Atom are very simple and allow many languages, but the last two specially allow for a lot of customisation and extensions, while the others are dedicated to Python with Thonny being for beginners and Pycharm and Spider for more advanced users.
2. Know which environments are for which tasks: Notebooks

Despite Machine Learning and Data Science being some sort of software development task which should be driven by the same principles as any other application, it does have some peculiarities that lead to exceptions when building applications.
The training and building of a Machine Learning pipeline from the data exploration, data treatments, feature selection, model building and tuning, is something quite empirical, iterative, and ‘scientific’. It is something more craft than automatic.
The mix of these Devops necessities, and these other more experimental needs leads to the creation and birth of MLOps. If you’ve heard about it before but never really got the hang of it, check out this delightfully explained article.
With this in mind, I wanted to go a bit into Jupyter Notebooks, which is one of the most used tools by Data Scientists and Machine Learning engineers these days. While they provide a great way to quickly explore our data, its distributions, different values, etc… they should not be abused, and should be used mainly for this exploratory work.
Data scientists should be aware that while Notebooks are a great interactive tool, they do not provide a great structure for coding, and should always have in mind that the code that they produce to train a model should later be ported to a productive environment where the model is going to be exploited.
Jupyter Notebooks and similar kinds of environments should be avoided whenever possible when putting Machine Learning models into production: they lack a defined sequential structure most times, when developing code many users create blocks to try little snippets that they later forget to delete, they do not have great version control capabilities, and they lack an structure which allows for testing, continuous integration, separation of software functionalities and so on…
In short: Jupyter Notebooks are a great analytical tool, but should be used with care, and the code built in them should be as tidy, parameterised, and encapsulated as possible. This will all make porting it to a productive environment much easier, and help when others have to re-use our work on one of this tools.
3. Correctly Set up your working virtual environments

Almost all software projects requiere some sort of libraries to execute. This is even more so in the Data Science realm, where very few times we build our programs from scratch.
Most times we use some sort of pre-made library like Sckit-Learn to accelerate the process and use out-of-the-box models that already work. Because of this, it is important to create different virtual environments, that encapsulate all the dependencies we need for an specific project.
Not doing so can lead to having to mess up the libraries of our base working environment, change to different versions for certain projects, and cause different issues that are painful and that can slow your development time by a lot.
Many IDEs, like Pycharm, can handle virtual environments for you if configured well, so the rule is the following: when tackling a big project that needs a lot of dependencies, create a new virtual environment for that project, and install from 0 all the libraries that you will need, with their correct versions.
Trust me, this will save you a lot of headaches.
4. Learn Git and use some sort of Version Control

Versioning the code you make and understanding how Git works is something essential if you want to get into professional software development, be able to work in teams, and correctly switch code in between environments.
Understanding the distributed nature of Git, and learning to use some of its most famous services like GitHub, GitLab, or Bitbucket is fundamental for any data scientist.
If you are not comfortable with these tools, your project execution pipeline will never be complete, and you will find yourself under nasty situations frequently.
There are a lot of resources out there for learning how to use Git and its associated services, however my advise would be to check them out quickly and then grab a friend and build a mini-project together. Make sure that you both code at least on one common script, so that you can face some of the challenges of these tools like conflicts and merge requests.
Be brave and don’t fear them: these are essential tools, and once you get the hang of them you will never forget again.
5. The SOLID principles

If you’ve never heard of them, the SOLID principles are the 5 fundamental principles of software development and architecture, which have the objective of guiding us, developers, towards creating efficient, robust, and escalable software, and towards writing clean and flexible code, which can be easily modified and that is maintainable and reusable.
In a few words: quality software. Knowing and working by the guidelines that these principles represent will make us better developers, and increase the quality of our programs and applications.
Lets see what each of the letters in SOLID stands for:
- S — Single Responsability Principle
- O — Open/Closed Principle
- L — Liskov Substitution Principle
- I — Interface Segregation Principle
- D — Dependency Inversion Principle
If you want to investigate and further study each individual principle, please do so, however, always keep in mind the ultimate goal they have: building software that is as good for the developers as for the users, and that follows certain design patterns that allow us to have highly efficient, reusable, and escalable software.
Belief me, once you interiorice them and start thinking about them when you are building your code, you will become a much much better developer.
6. Learn object oriented programming

Carrying on with the line started on the previous section, Object Oriented Programming or OOP is a programming methodology that greatly exemplifies the SOLID principles.
Some programming languages are more strict than others about how they impose OOP (Java for example is quite strict while Python is not), however in most modern language some sort of OOP is always present, so understanding what it is and how it works will lead you to not only coding better programs, but also to understanding functionalities of existing code and libraries much better.
Classes and their associated objects should encapsulate different functionalities: for example, in the Data Science world, when you put models into production, you can encapsulate in a single class all the data treatments, and make sure that the class is generic enough so that future treatments can be easily added in the future if needed.
Also, all the lovely libraries that we use, like Scikit-Learn, provide most functions through classes: the .fit( ) or .predict( ) methods that we use all the time to train our models and make our predictions are no more than methods of the Estimator classes like RandomForestClassifier or LogisticRegression.
Knowing the internal workings of these libraries can make us much more efficient when using them or when debugging errors.
7. Find comfort in the Command Line

The command line is an incredible tool that any programmer should learn to use. Despite seeming scary with its deep black screen, it not only allows you to access the most powerful capabilities of your personal computer, but it is also required to execute git commands, launch and create docker images, and access remote servers through ssh.
As a Data Scientist, you will find yourself having to use it many times. When this happens, you should not feel fear, but comfort instead. You should see the command line as an extension of your favourite IDE, even more, you should probably have a plugging inside this IDE that lets you access the command line directly to launch quick scripts and tests.
I was scared of it at first too, but by being brave and deciding to use it whenever I could, my fear went away and now I code in there and use commands like if I had been doing it all my life.
There are many resources out there to learn to use the command line, and the syntax of the operations is different in Windows Systems than in UNIX (Linux and Mac), so I would advice you to first get comfy with the UNIX way, creating directories, moving around in the directory tree, searching for documents, and editing them through the CLI, and then going to Windows if you think you will need it at some point, or if the system you use in your day to day is not UNIX.
8. Training on the push of a button

Some of the last sections we’ve spoken about were directed towards generic developers, specifying tools or methodologies that they should use. This one however is directly solely towards Data Scientists and Machine Learning engineers.
Data preparation, feature selection, and model building are generally tough of as a highly artesanal and craft endeavour. For the most part, they requiere the developer to see step by step what the output of each section is, retry things, etc…
However, once we have our final Dataframe (the one we will use for the model training) ready and clean, our features created, etc…we can automate the rest of the process, press enter, and wait for results.
What do I mean by this? Feature selection, pre-model treatments like feature scaling or dimensionality reduction, and lastly model building and tuning, can all be set on automated pipelines and spit the results as they finish.
Imagine we have built a Dataframe with a certain dataset, eliminated correlated variables, imputed null values, create dummies, etc… Our data is ready for model building. However, we don’t know which treatments we want to use, or which features are the most important. If I train a Logistic Regression…will the features calculated using Random Forest feature importance work? They will give me a good idea, but they are not the best fit for this model.
If you have enough coding expertise, know how to program in classes, and are willing to spend the initial time to learn how to do this, you can automate all this process so you don’t have to make any intermediate choices: you just pick the resulting pipeline with the best results.
I know, I know, many of you will be thinking: through Scikit-Learn Pipelines (which are nothing else than a class) and GridSearchCV (another class) I can do all you are talking about. Well, you can do most of it, but probably not all, and being able to build your own automated pipelines will give you flexibility and a lot of power.
To consolidate all this in your mind, lets see an example. Imagine you are doing an unsupervised clustering algorithm. Here you don’t have a grid search, or at least not in the traditional manner, so bye to that. Also, you want to try different scaling techniques, and are considering doing a PCA before the model building. Lastly, you don’t know if Kmeans will work well, or if you might have to resort to some other kind of model like DBSCAN.
By building classes that create an abstraction for the treatments and the models, you can configure scripts that depending on the change of one variable from ‘pca’ to ‘kernel_pca’ or from ‘kmeans’ to ‘dbscan’, will execute different pipelines and in the end spit out the result while you sit there, read Reddit, and have a coffee.
See the power?
9. Training and Application

This is another highly relevant topic. Machine Learning engineers and Data Scientist should have a clear distinction in their mind between these two, as they refer to very different processes.
I’ve introduced this various times, but it is something so essential that I want to make it completely clear. When we do the training process, which we’ve spoken about in the previous section, a part of it is highly experimental. We try different feature combinations, different treatments, and even models, resulting in a series of numbers like the following:
- 40 Variables, Normalisation, and Logistic Regression — AUC: 0.81
- 52 Variables, No feature scaling, and Logistic Regression — AUC: 0.83
- 48 Variables, Standardisation, and Random Forest — AUC: 0.85
- …
Once we see these results, we can pick the best functioning model, or choose a compromise between metric and number of variables (the less variables there are in the model the less ‘failure points’ we have, and the easier it is to understand and debug), and then manually redo all the process of building that model and training it, checking the process step by step and even tuning it a little bit further.
Once this is done, we extract a serialised object, like a .pkl from the training and that is that.
If we were building a Proof of Concept or POC to show how good metrics our model get, then the work up to this point would be enough. However, while POCs are cool, we want to see our model working. Integrated. Providing real value. And for this, we have to build an app, put it into production.
This production pipeline is different than the training one. It is not iterative. We don’t need to experiment. It is something that is probably more similar to t traditional software development than to Data Science. But it needs to be done. And it needs to be done well.
Here we can have the support of Data Engineers, but the clear differentiation in the mind of a Data Scientist between these two processes is fundamental for the theoretical part of the training (how you build your modelling dataframe) and for the practical part of the application (how you translate what you’ve done in the training to a productive environment where the model can be exploited).
I hope that with this section it has become even more clear.
10. Extras: Testing, CI/CD…

Picking up from the previous section, this last one covers some topics which are very well known in the software development world, but which are given less importance in the realm of Data Science.
This is derived from what we’ve spoken about before: Data Scientists and Machine Learning engineers usually have a lot of analytical skills, but lack Computer Science and Software Development knowledge.
In the software realm, tests are something which is ALWAYS done before deploying a code into production, to guarantee that this code works well, it does not have any bugs, and it can only be accessed by those who should be able to access it. These tests are usually very thorough, and eat up a good chunk of any software project time.
There are two main kinds of tests, unit tests, which guarantee that individual functionalities of our code work well, like for example a button taking us to the screen it should on a phone up, or that a JSON is well read and converted to a Dataframe in a Data Science up. Also, there are integration tests, that try to see if all the different parts of our software are well connected: for example, seeing if an SQL Database is accesible when it is needed from another environment, like for example Azure Databricks.
The last step towards the Holy Grail of software development are Continous Integration and Continous Development or CI/CD. They integrate version control, merge approvals, incorporation of new functionalities, tests, and production deployments.
When a new version of our software is developed, merge request is made, and the new code is review by peers. If this review is accepted, then the new version is evaluated by the tests, and in case it passes them, it is uploaded to a superior (production or pre-production environment) where it should live. This is an optimal methodology that is seen a lot in the software development realm, and not so much in the world of Data Science.
Conclusion, closing words, and further resources
With the previous article I’ve wanted to outline some tips for writting code, and software development in general, that I think will help any Data Scientist out there who feels a bit scared or shy of developing methodologies.
By picking up a little bit on each of the points, studying them superficially, and most importantly, getting your hands dirty and trying them out, you will level up your software practices undoubtedly.
I hope the advice found on this article was useful, and I wish you the best of luck.
For more advice and posts like this follow me on Twitter, and to find reviews of the different books I have spoken about, check out the following repository.
Have a wonderful day and enjoy AI!